This post originally appeared on Medium.
Archiving Video from #Ferguson
404 page for the 11th most-linked Vine from the Ferguson Twitter Archive
In Documenting the Now: #Ferguson in the Archives, Bergis Jules highlighted the importance of photo and video content to the events of Ferguson. In thinking about ways to practically achieve archiving this content, I realized a program called youtube-dl (which downloads videos not just from YouTube, but from a number of sites) would be pretty well-suited for the job and wrote a short script to call it for every URL in Ed Summers’ Ferguson Twitter archive. After some initial mis-steps, I decided to prioritize processing videos from Vine first (where the six second limit makes it a far more tractable corpus than the entire set of URLs):
Initial results of running https://t.co/nw1ZbEoPDn to extract Vines from Ferguson archive: 4,038 videos in 3.3GB, 556 404 not found errors
— Ryan Baumann (@ryanfb) April 9, 2015
That’s nice and all, and gives us some simple statistics for estimating the size of this subset of the data, an idea of what might already be at risk for going unarchived, and a local copy of the data in case Vine announces they’ve come to the end of their incredible journey tomorrow.
But what can we actually do with the data?
I think that question, and the questions I came up with in the process of trying to answer it, are important ones to think about and discuss for this or any other similar social media video archive. Some of these issues are similar to the issues Ed has wrestled with for the Twitter archive itself, while others may be unique to the medium of video.
How do we share such an archive? How do we mediate it, curate it, present it, and make it available to others?
How do we decide which videos are “important” or “related” to Ferguson? Which videos do we want to keep? Some popular links in the Twitter archive are to a specific Vine/YouTube/Instagram user account, which may have been posting about Ferguson at the time, but have other videos on their accounts as well.
What sorts of statistical analyses and visualizations can we use to examine this data? Is there anything interesting we could discover from analyzing “just metadata” (title, description, uploader, timestamp, comments, views, likes, reposts, linking tweets, video length)? Could we trace the spread of popular videos? Some of these things might require establishing links between URLs from the archive and videos from the archive, something the current process doesn’t record (and which may be a many-to-many relationship).
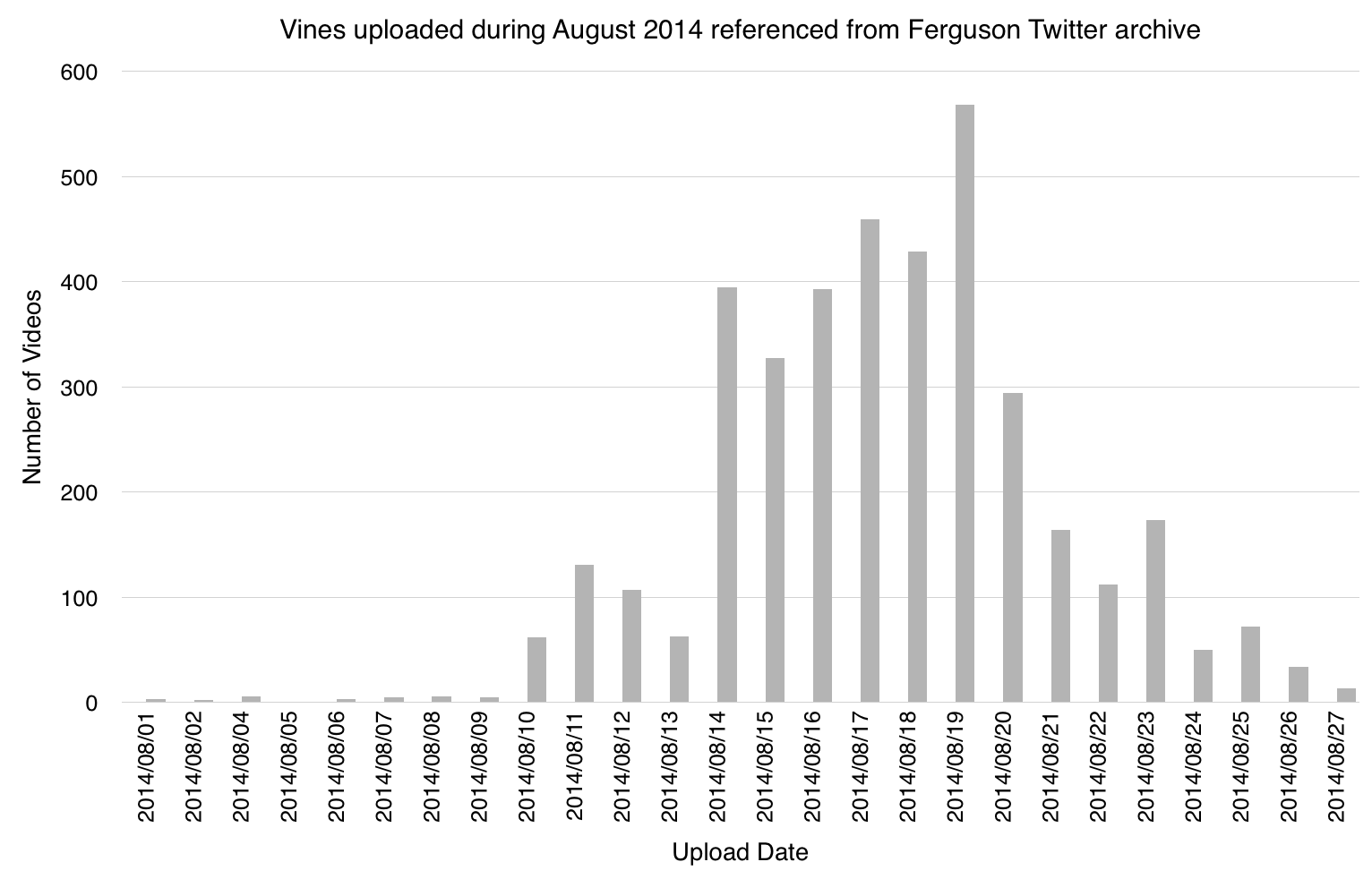
Histogram distribution of upload date for Vines from the Ferguson Twitter archive
What sorts of audio, video, or image processing could we do against this archive? Can we detect video re-posting/re-use (Vines used in news stories, for example)? Could we automatically classify videos based on their contents? Could we geolocate and timestamp videos? Could we apply facial recognition algorithms? What would we hope to learn from these tasks?
What are the ethics of trying to recover/archive missing videos? Many of these videos are on personal accounts. Perhaps some are cases of people just deleting their account, and not realizing they might be inadvertently deleting a piece of history. Perhaps others are cases where people explicitly wished to remove a specific video or painful memories. We have no real way of knowing. But this also raises the question of how to address these problems in prospective archiving; if we had run this video archival process alongside the original Twitter archive process, we would probably have far fewer “not found” videos, but that doesn’t remove the ethical question about people exercising their right to be forgotten.
